渗透基础——选择一个合适的C2域名
0x00 前言
在渗透测试中,常常需要选择一个合适的域名作为c2服务器,那么什么样的域名才能称之为”合适”呢?
expireddomains.net也许能够给你一些思路。
通过expireddomains.net能够查询到最近过期或删除的域名,更重要的是它提供了关键词搜索功能。
本文将要测试过期域名自动化搜索工具CatMyFish,分析原理,修正其中的bug,使用python编写一个爬虫,获得所有搜索结果。
0x01 简介
本文将要介绍以下内容:
- 测试过期域名自动化搜索工具CatMyFish
- 分析原理修正CatMyFish中的bug
- 爬虫开发思路和实现细节
- 开源python实现的爬虫代码
0x02 测试过期域名自动化搜索工具CatMyFish
下载地址:
https://github.com/Mr-Un1k0d3r/CatMyFish
主要实现流程
- 用户输入关键词
- 脚本将搜索请求发送到expireddomains.net进行查询
- 获得域名列表
- 脚本将域名发送到Symantec BlueCoat进行查询
- 获取每个域名的类别
expireddomains.net地址:
https://www.expireddomains.net/
Symantec BlueCoat地址:
https://sitereview.bluecoat.com/
实际测试
需要安装python库beautifulsoup4
pip install beautifulsoup4
尝试搜索关键词microsoft,脚本报错,如下图
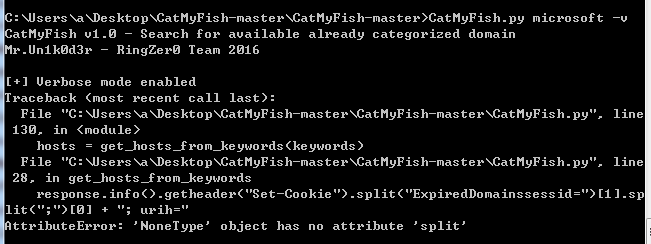
脚本对结果的解析出现了问题
于是,按照CatMyFish的实现思路自己编写脚本测试一下
访问expireddomains.net查询关键词microsoft,代码如下:
import urllib
import urllib2
from bs4 import BeautifulSoup
url = "https://www.expireddomains.net/domain-name-search/?q=microsoft"
req = urllib2.Request(url)
res_data = urllib2.urlopen(req)
html = BeautifulSoup(res_data.read(), "html.parser")
tds = html.findAll("td", {"class": "field_domain"})
for td in tds:
for a in td.findAll("a", {"class": "namelinks"}):
print a.text
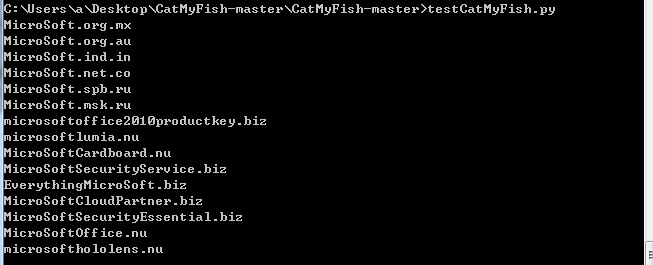
共获得15个结果,如下图
通过浏览器访问,共获得25个结果,如下图
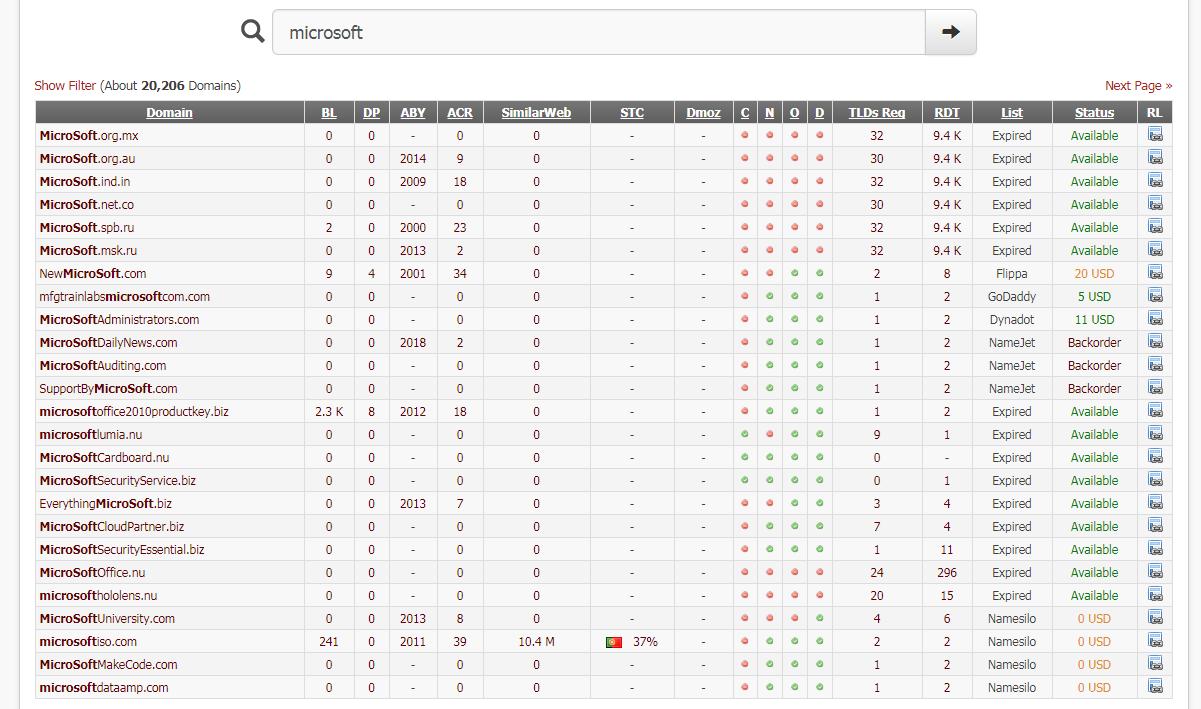
经过对比发现通过脚本获得的数目相比浏览器要少,应该是脚本在筛选的时候出现了问题
注:
初学者建议掌握一下beautifulsoup4的基本使用技巧,本文暂略
0x03 查找bug原因
1、根据response查看域名标签,对筛选规则进行判断
需要获取到接收到的response数据,通过查看各个域名对应的标签,判断是否在标签筛选的时候出现了问题
查看response数据的两种方法:
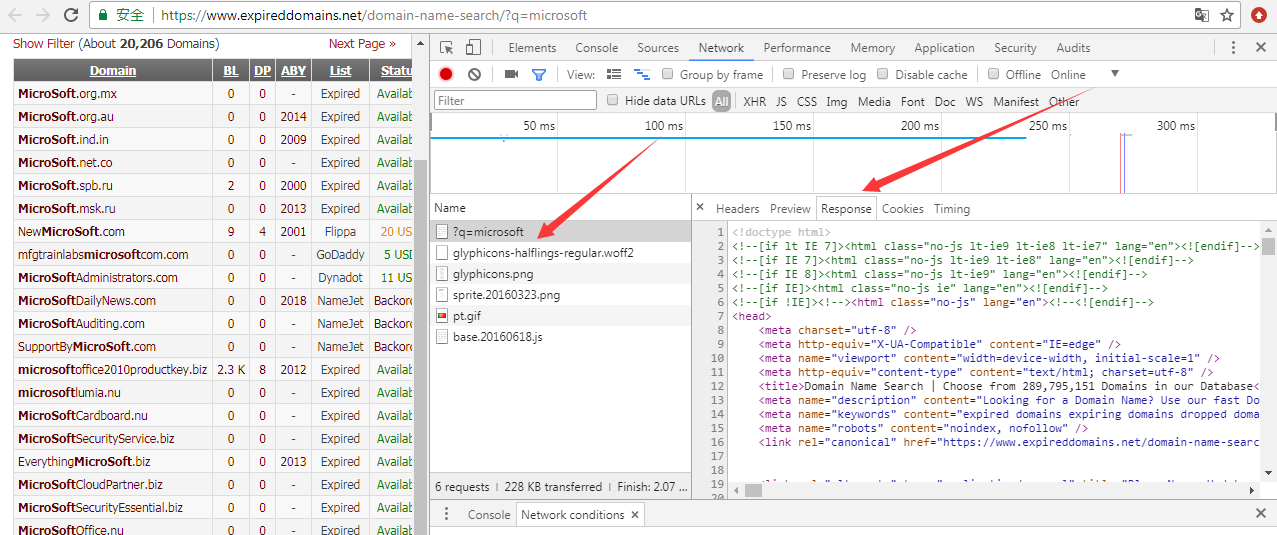
(1) 使用Chrome浏览器查看
F12 -> More tools -> Network conditions
重新加载网页,选择?q=microsoft -> Resonse
如下图
(2) 使用python脚本
代码如下:
import urllib
import urllib2
url = "https://www.expireddomains.net/domain-name-search/?q=microsoft"
req = urllib2.Request(url)
res_data = urllib2.urlopen(req)
print res_data.read()
分析response数据,发现出错原因:
使用原测试脚本能够提取出如下数据中的域名:
<td class="field_domain"><a class="namelinks" href="/goto/1/71h90s/59/?tr=search" id="linksdd-domain71h90s" rel="nofollow" target="_blank" title="MicroSoft.msk.ru"><strong>MicroSoft</strong>.msk.ru</a><ul class="kmenucontent" id="links-domain71h90s" style="display:none;"><li class="first"><a class="favicons favgodaddy" href="/goto/16/75wxyx/59/?tr=search" rel="nofollow" target="_blank" title="Register at GoDaddy.com">GoDaddy.com</a></li><li><a class="favicons favdynadot" href="/goto/53/740s95/59/?tr=search" rel="nofollow" target="_blank" title="Register at Dynadot.com">Dynadot.com</a></li><li><a class="favicons favuniregistry" href="/goto/66/7252us/59/?tr=search" rel="nofollow" target="_blank" title="Register at Uniregistry.com">Uniregistry.com</a></li><li><a class="favicons favnamecheap" href="/goto/43/7459ux/59/?tr=search" rel="nofollow" target="_blank" title="Register at Namecheap.com">Namecheap.com</a></li><li><a class="favicons favonecom" href="/goto/57/71gmkr/59/?tr=search" rel="nofollow" target="_blank" title="Register at One.com">One.com</a></li><li><a class="favicons fav123reg" href="/goto/48/7254ap/59/?tr=search" rel="nofollow" target="_blank" title="Register at 123-reg.co.uk">123-reg.co.uk</a></li></ul></td>
但是response数据中还包含另一种类型的数据:
<td class="field_domain"><a href="/goto/1/4o47ng/39/?tr=search" rel="nofollow" target="_blank" title="NewMicroSoft.com">New<strong>MicroSoft</strong>.com</a></td>
原测试脚本没有提取该标签中保存的域名信息
0x04 bug修复
筛选思路:
获得标签<td class="field_domain">中第一个title的内容
原因:
这样能同时获得两组数据中保存的域名信息,过滤无效信息(如第二个title中的域名GoDaddy.com)
实现代码:
tds = html.findAll("td", {"class": "field_domain"})
for td in tds:
print td.findAll("a")[0]["title"]
因此,获得完整查询结果的测试代码如下:
import urllib
import urllib2
import sys
from bs4 import BeautifulSoup
def SearchExpireddomains(key):
url = "https://www.expireddomains.net/domain-name-search/?q=" + key
req = urllib2.Request(url)
res_data = urllib2.urlopen(req)
html = BeautifulSoup(res_data.read(), "html.parser")
tds = html.findAll("td", {"class": "field_domain"})
for td in tds:
print td.findAll("a")[0]["title"]
if __name__ == "__main__":
SearchExpireddomains(sys.argv[1])
成功获得第一页的所有结果,测试如下图
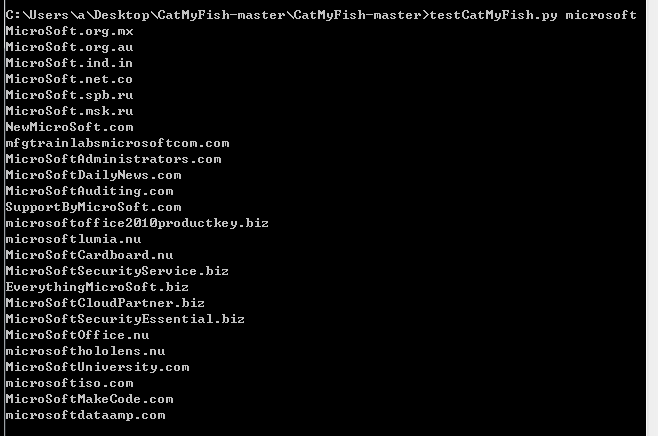
0x05 获得所有查询结果
expireddomains.net每页保存25个结果,想要获得所有结果,需要发送多个请求,遍历所有查询页面的结果
首先需要获得所有结果的数目,除以25获得需要查询的页面个数
1、统计所有结果
查看Response,找到表示搜索结果数目的位置,内容如下:
<div class="pagescode page_top">
<div class="addoptions left">
<span class="showfilter">Show Filter</span>
<span>(About <strong>20,213 </strong> Domains)</span>
Chrome浏览器显示如下图
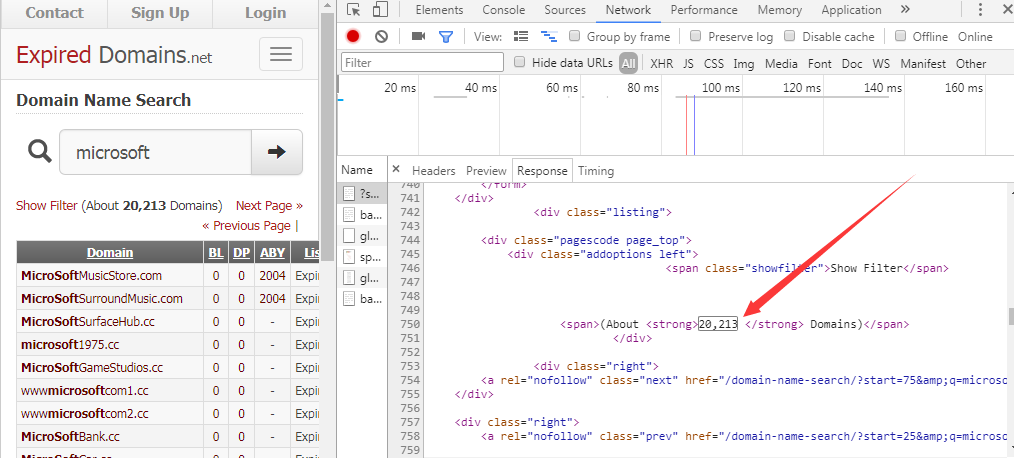
为了简化代码长度,使用select()直接传入CSS选择器进行筛选,在对标签strong进行筛选后,第1个标签表示结果数目,对应查询代码为:
print html.select('strong')[0]
输出结果为<strong>20,213 </strong>
提取其中的数字:
print html.select('strong')[0].text
输出结果为20,213
去掉中间的”,”:
print html.select('strong')[0].text.replace(',', '')
输出结果为20213
除以25即可获得需要查询的页面个数,这里需要注意需要将字符串类型的”20213”转换为整型20213
2、猜测查询规律
第二页查询的url:
https://www.expireddomains.net/domain-name-search/?start=25&q=microsoft
第三页查询的url:
https://www.expireddomains.net/domain-name-search/?start=50&q=microsoft
找到查询规律,第i页查询的url:
https://www.expireddomains.net/domain-name-search/?start=<25*(i-1))>&q=microsoft
注:
经测试,expireddomains.net对未登录用户最多提供550个的结果,共21页
3、对结果进行判断
在脚本实现上,需要对结果进行判断,如果结果大于550,只输出21页,如果小于550,输出<结果/25>页
4、模拟浏览器访问(备选)
当我们使用脚本尝试自动查询多个页面时,如果网站使用了反爬虫机制,无法获得真实数据
经测试,expireddomains.net并未开启反爬虫机制
如果在将来,expireddomains.net开启了反爬虫机制,脚本需要模拟浏览器发送请求,在头部附加User-Agent等信息
查看Chrome浏览器获得发送请求的信息,如下图
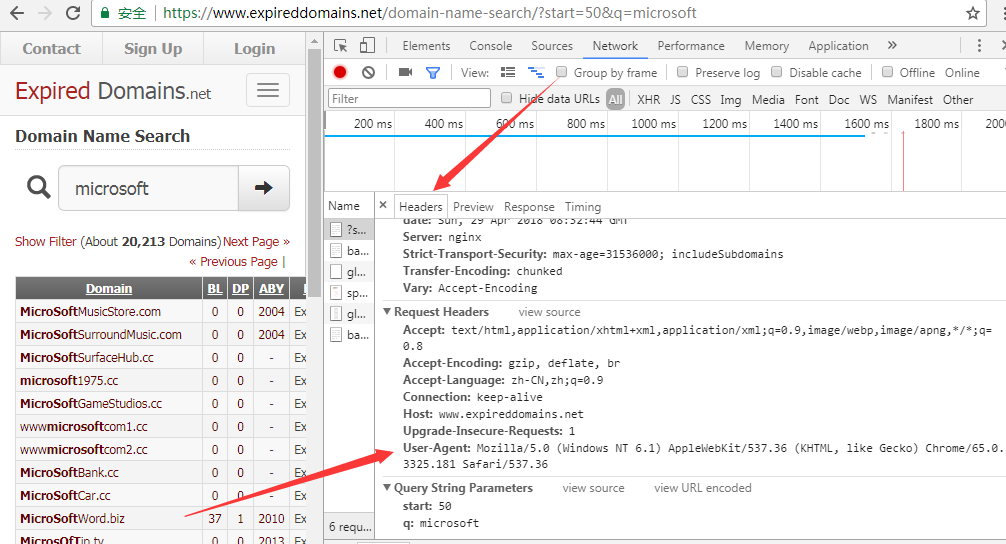
对照请求,添加头部信息即可绕过
示例代码:
req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
完整代码实现地址:
https://github.com/3gstudent/GetExpiredDomains
实际测试:
搜索关键词microsoftoffices,结果少于550,如下图
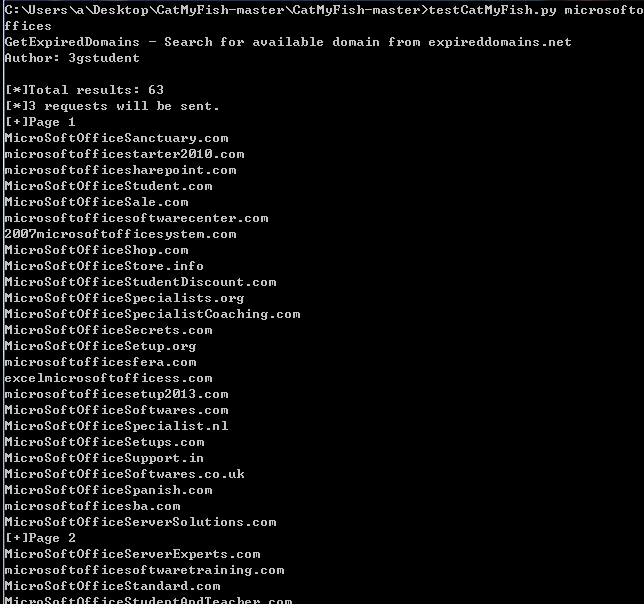
搜索关键词microsoft,结果大于550,只显示21页,如图
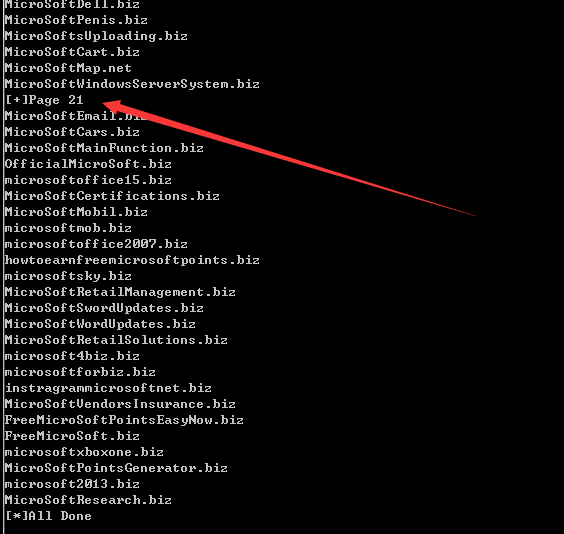
同Web访问的内容对比,结果相同,测试成功
0x06 小结
本文测试了过期域名自动化搜索工具CatMyFish,分析原理,修正其中的bug,使用python编写爬虫获得所有搜集结果,分享开发思路,开源代码。