Exchange Web Service(EWS)开发指南3——SOAP XML Parser
0x00 前言
在之前的文章《Exchange Web Service(EWS)开发指南2——SOAP XML message》介绍了SOAP XML message的使用,通过Python实现了利用hash对Exchange资源的访问。
当我们通过SOAP XML message读取邮件时,尝尝会遇到以下麻烦:由于每一封邮件对应一份原始的XML文件,原始的XML文件包含完整的邮件信息,人工分析邮件将耗费大量精力。
于是,本文将要介绍一种SOAP XML解析器的实现方法,编写工具实现自动提取有价值的邮件信息,提高阅读效率。
0x01 简介
本文将要介绍以下内容:
- 适用环境
- 设计思路
- 开源Python实现代码
- 代码开发细节
0x02 设计思路
通过SOAP XML message读取收件箱中的所有邮件,需要以下步骤:
- 使用ewsManage.py的listmailofinbox命令获得每一封邮件的ItemId和ChangeKey
- 循环使用ewsManage.py的getmail命令,传入每封邮件对应的ItemId和ChangeKey
- 分别将返回结果保存为XML格式的文件,每一个XML文件对应一封邮件
为了保证SOAP XML解析器的通用性,能够配合不同的工具,所以将SOAP XML解析器设计成了文件管理器的结构,选中XML文件将会自动解析,提取有价值的信息并显示,在设计上遵循以下原则:
- 开发语言选用Python,为了提高便捷性,全部使用Python的标准库
- 文件管理器涉及到Python的界面开发,使用标准GUI库
Tkinter - SOAP(Simple Object Access Protocol)协议在本质上仍为XML协议,在解析上使用标准库
xml.dom.minidom
注:
如果使用字符串匹配的方式对XML文件解析,还需要考虑转义字符
0x03 程序实现
1.文件管理器的实现
Tkinter的使用:
https://docs.python.org/3/library/tk.html
这里可以基于开源的file-manager-mask进行二次开发,修改如下部分:
- 去掉图片显示功能
- 去掉编辑文本的功能
- 添加XML文件解析的功能
2.XML文件解析
xml.dom.minidom的使用:
https://docs.python.org/3/library/xml.dom.minidom.html
这里需要提取以下内容:
- 邮件标题
- 发件人
- 收件人
- 抄送
- 接收时间
- 附件名称
- 正文内容
在数据提取上有以下不同的情况:
注:
XML标签对大小写敏感
(1)提取节点属性
响应消息的格式示例:
<m:GetItemResponseMessage ResponseClass="Success">
提取节点"m:GetItemResponseMessage"的属性"ResponseClass",代码如下:
from xml.dom import minidom
dom = minidom.parse("TestMail.xml")
data_response = dom.getElementsByTagName("m:GetItemResponseMessage")
print(data_response[0].getAttribute("ResponseClass"))
(2)直接提取标签对之间的数据
邮件标题的格式示例:
<t:Subject>123</t:Subject>
正文内容的格式示例:
<t:Body BodyType="Text" IsTruncated="false">123</t:Body>
接收时间的格式示例:
<t:DateTimeReceived>2021-01-11T11:08:50Z</t:DateTimeReceived>
提取节点"t:Subject"的内容,代码如下:
from xml.dom import minidom
dom = minidom.parse("TestMail.xml")
data_subject = dom.getElementsByTagName("t:Subject")
print(data_subject[0].firstChild.data)
发件人的格式示例:
<t:Sender>
<t:Mailbox>
<t:Name>test1</t:Name>
<t:EmailAddress>test1@test.com</t:EmailAddress>
<t:RoutingType>SMTP</t:RoutingType>
<t:MailboxType>Mailbox</t:MailboxType>
</t:Mailbox>
</t:Sender>
这里需要考虑父节点和子节点
注:
发件人通常只有一个,所以不需要考虑循环提取
提取父节点"t:Sender"的子节点"t:Name"内容,代码如下:
from xml.dom import minidom
dom = minidom.parse("TestMail.xml")
data_from = dom.getElementsByTagName("t:Sender")
print(data_from[0].getElementsByTagName("t:Name")[0].firstChild.data)
(3)循环提取标签对之间的数据
收件人的格式示例:
<t:ToRecipients>
<t:Mailbox>
<t:Name>test2</t:Name>
<t:EmailAddress>test2@test.com</t:EmailAddress>
<t:RoutingType>SMTP</t:RoutingType>
<t:MailboxType>Mailbox</t:MailboxType>
</t:Mailbox>
<t:Mailbox>
<t:Name>test3</t:Name>
<t:EmailAddress>test3@test.com</t:EmailAddress>
<t:RoutingType>SMTP</t:RoutingType>
<t:MailboxType>Mailbox</t:MailboxType>
</t:Mailbox>
</t:ToRecipients>
抄送人的格式示例:
<t:CcRecipients>
<t:Mailbox>
<t:Name>test2</t:Name>
<t:EmailAddress>test2@test.com</t:EmailAddress>
<t:RoutingType>SMTP</t:RoutingType>
<t:MailboxType>Mailbox</t:MailboxType>
</t:Mailbox>
<t:Mailbox>
<t:Name>test3</t:Name>
<t:EmailAddress>test3@test.com</t:EmailAddress>
<t:RoutingType>SMTP</t:RoutingType>
<t:MailboxType>Mailbox</t:MailboxType>
</t:Mailbox>
</t:CcRecipients>
附件的格式示例:
<t:Attachments>
<t:FileAttachment>
<t:AttachmentId Id="AAMk**1"/>
<t:Name>image1.jpg</t:Name>
<t:ContentType>image/jpeg</t:ContentType>
<t:ContentId>image1.jpg@11111111.11111111</t:ContentId>
<t:Size>1024</t:Size>
<t:LastModifiedTime>2021-01-01T01:01:01</t:LastModifiedTime>
<t:IsInline>true</t:IsInline>
<t:IsContactPhoto>false</t:IsContactPhoto>
</t:FileAttachment>
<t:FileAttachment>
<t:AttachmentId Id="AAMk**2"/>
<t:Name>image2.jpg</t:Name>
<t:ContentType>image/jpeg</t:ContentType>
<t:ContentId>image2.jpg@11111111.11111112</t:ContentId>
<t:Size>1024</t:Size>
<t:LastModifiedTime>2021-01-01T01:01:01</t:LastModifiedTime>
<t:IsInline>true</t:IsInline>
<t:IsContactPhoto>false</t:IsContactPhoto>
</t:FileAttachment>
</t:Attachments>
这里需要考虑父节点和兄弟节点
提取父节点"t:ToRecipients"的所有子节点"t:Name"的内容,代码如下:
from xml.dom import minidom
dom = minidom.parse("TestMail.xml")
data_to = dom.getElementsByTagName("t:ToRecipients")
data_to_name = data_to[0].getElementsByTagName("t:Name")
for i in range(len(data_to_name)):
print(data_to_name[i].firstChild.data)
以上代码跳过了对节点"t:Mailbox"的判断,如果加上判断,代码如下:
from xml.dom import minidom
dom = minidom.parse("TestMail.xml")
data_to = dom.getElementsByTagName("t:ToRecipients")
data_to_mailbox = data_to[0].getElementsByTagName("t:Mailbox")
for i in range(len(data_to_mailbox)):
print(data_to_mailbox[i].getElementsByTagName("t:Name")[0].firstChild.data)
当完成了对XML文件的数据提取后,需要考虑如何将数据显示到文件管理器的窗口上
这里要用到insert函数
参数说明:
https://docs.python.org/3.8/library/tkinter.ttk.html?highlight=insert#tkinter.ttk.Notebook.insert
insert(pos, child, **kw)
Inserts a pane at the specified position.
对于参数pos,END代表从最后一行插入,数字代表从指定行插入(例如第一行为1.0)
完整的代码已上传至Github,地址如下:
https://github.com/3gstudent/Homework-of-Python/blob/master/Exchange_EWS_XML_Parser.py
代码支持以下功能:
- 文件管理器,便于查看多个文件,可以通过键盘方向键实现文件切换
- XML文件解析,能够从Exchange SOAP XML message中自动提取出有价值的信息,标记不符合格式的XML文件
运行界面如下图:
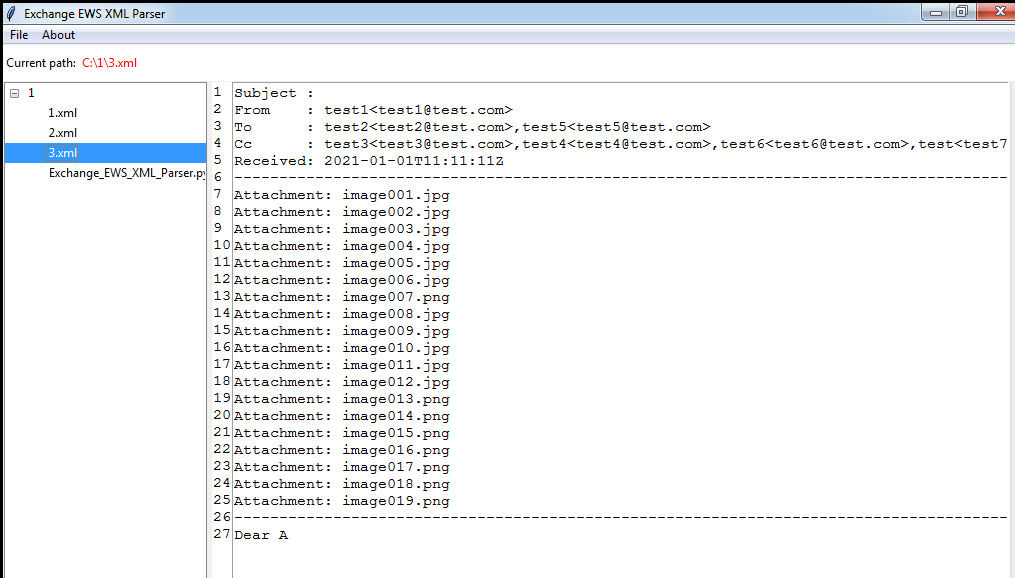
后续可以结合ewsManage.py开发完整的Exchange界面化客户端程序,实现利用hash读取Exchange邮件
0x04 小结
本文介绍了一种SOAP XML解析器的实现方法,编写工具实现自动从Exchange SOAP XML message中提取邮件信息,开源Python实现代码,分析代码开发细节